前々から出るぞ出るぞと言われていたOpenAIのオープンウェイトリーズニングモデルである、「gpt-oss」が2025年8月5日にリリースされました。
リリースされたモデルはgpt-oss-120bとgpt-oss-20bの2つで、gpt-oss-120bはVRAM 80GBの単一GPUでコア推論ベンチマークで、OpenAI o4-miniとほぼ同等の結果を得られるモデルのよう。
gpt-oss-20bは一般的なベンチマークでOpenAI o3‑miniと同様の性能を発揮し、16GBメモリを搭載したエッジデバイス(サーバのように大規模な環境ではなく、手元のクライアントPC)で実行できるようです。
LM Studioでも早速Staff Pickモデルとして2つのモデルがダウンロードできるようになっていたので、僕のメインマシンと、M4 mac miniの一番下位のモデルの環境でそれぞれ試してみました。
目次
テスト環境
今回テストした環境は筆者メインマシンと、Thunderboltブリッジでexoのクラスタ組むぞ~って考えて、購入した一番下位モデルの16GBユニファイドメモリを搭載したM4 mac mini。
メインマシンの主なスペックは以下の通りです。
| CPU | AMD Ryzen 7 9700X |
| RAM | DDR5-5600 64GB×2 |
| GPU | AMD Radeon RX 9070 |
| モデルを保存しているNVMe | Intel SSD 670p |
トークン出力の速度比較
LLMのベンチマークにそこまで明るいわけではないので、視覚的に分りやすい1秒当たりに出力できるトークン数で比較してみました。
gpt-oss-20b テストパターン
テストパターンは以下の通りです。
- パターンA:【メインマシン】コンテキスト長:4096、GPUオフロード:24
- パターンB:【メインマシン】コンテキスト長:4096、GPUオフロード:23 ※デフォルト値
- パターンC:【M4 mac mini】コンテキスト長:4096、GPUオフロード:20
- パターンD:【M4 mac mini】コンテキスト長:4096、GPUオフロード:15 ※デフォルト値
テストで利用したプロンプト
僕がよくLM Studioをぶん回したときのテストで使っている下記のプロンプトをそれぞれのテストで利用します。
ある都市で新型の感染症が流行し始めています。感染症の基本再生産数(R0)は2.5で、人口は100万人、初期感染者は100人です。ワクチンの接種率が50%の場合、感染拡大を抑えるためには追加でどれだけの人がワクチンを接種する必要がありますか?また、感染拡大を防ぐための他の公衆衛生対策を3つ挙げ、それぞれの効果と課題を論理的に説明してください。結果
それぞれのパターンでテストプロンプトを実行した結果は以下の通りです。
| パターン | 1秒あたりに出力できるトークン数(tok/sec) |
| パターンA | 122.34 tok/sec |
| パターンB | 44.98 tok/sec |
| パターンC | 17.52 tok/sec |
| パターンD | 19.45 tok/sec |
メインマシンで実行したパターンAがめちゃ早い
こうして結果を見てみると、メインマシンでGPUオフロードを最大値に設定した「パターンA」の結果は驚異的で、結果の出力も一瞬で済みます。
あまりにも早くて笑いそうになったので、実行時の様子をGIFアニメーションで録画してみました。
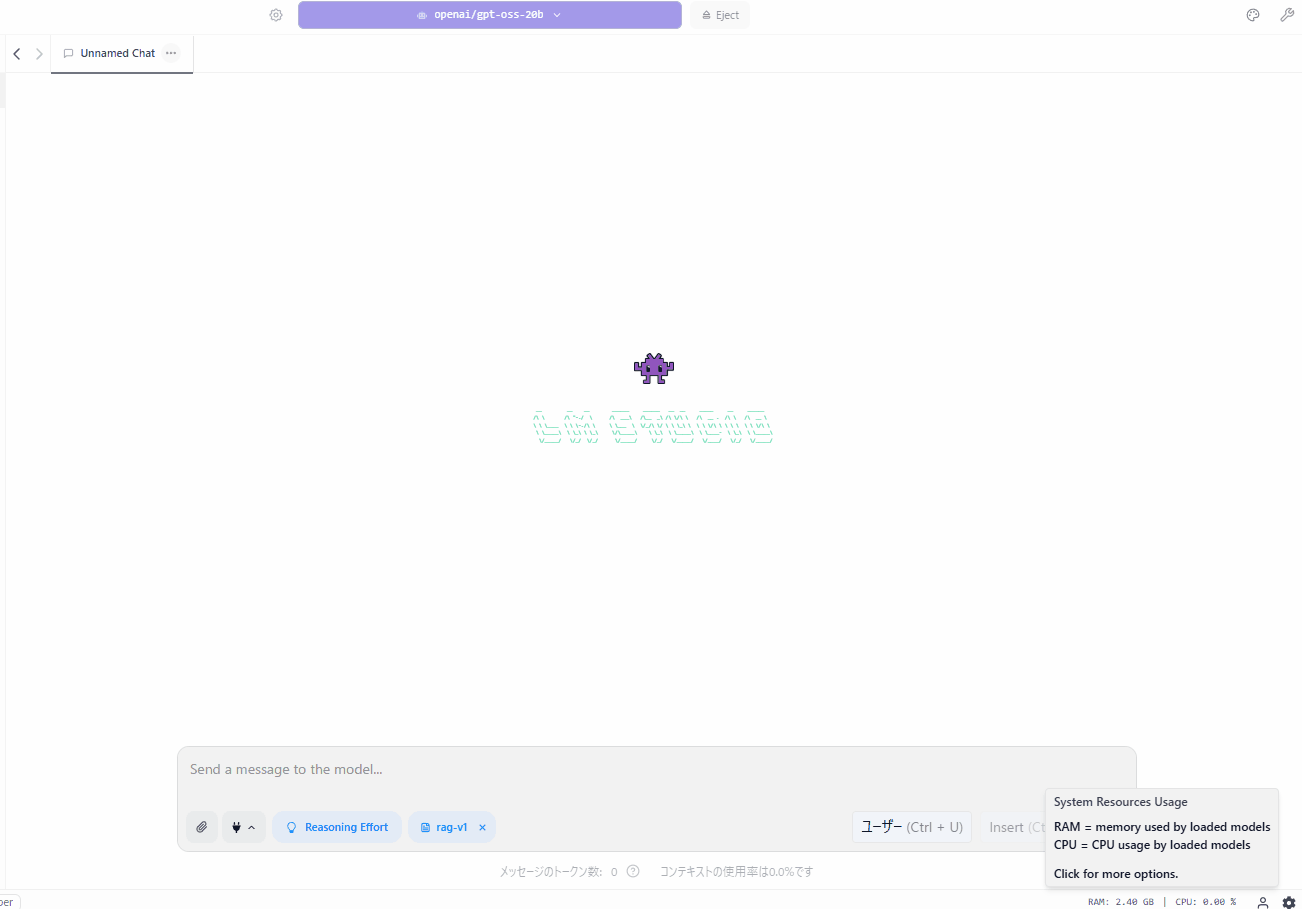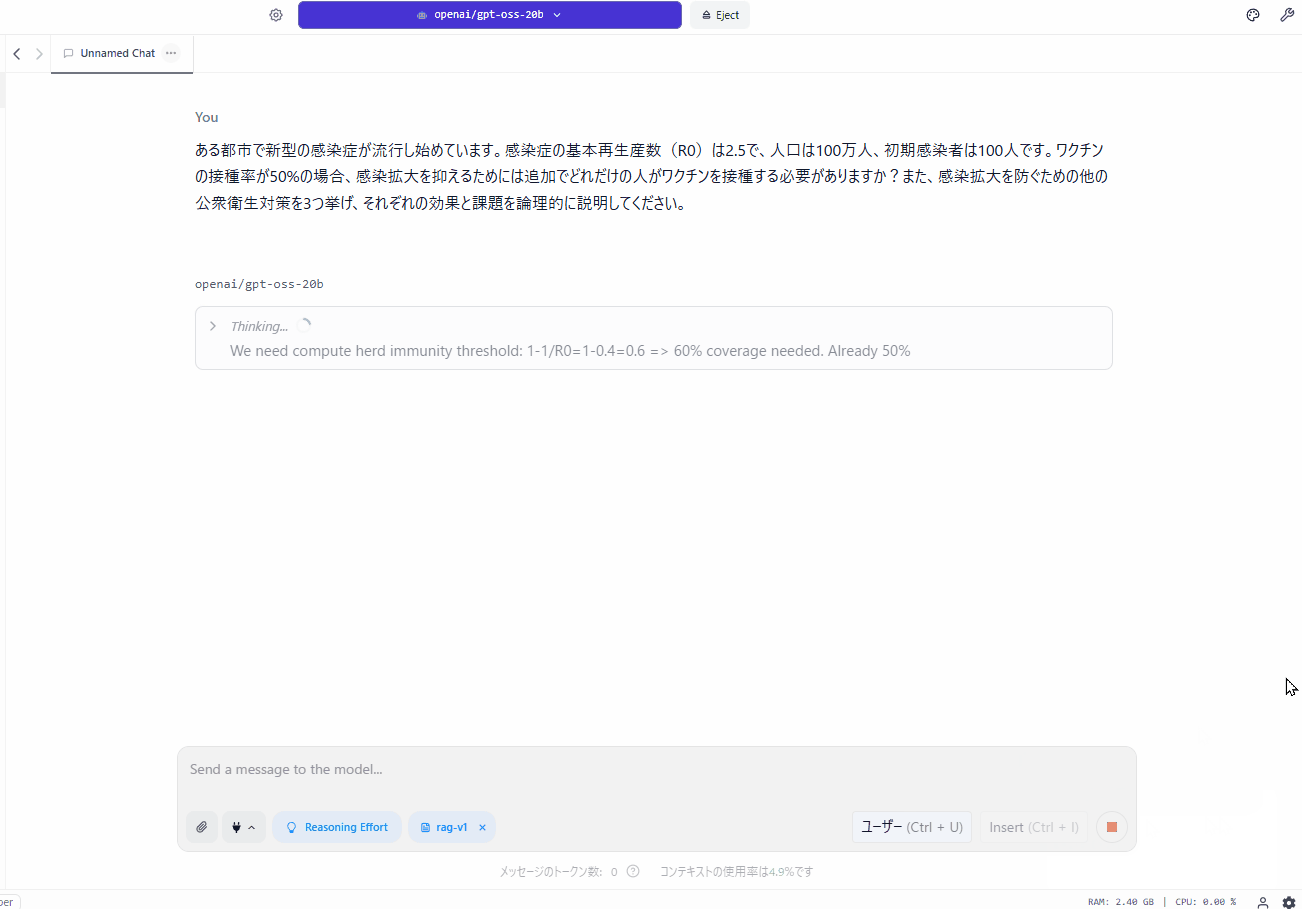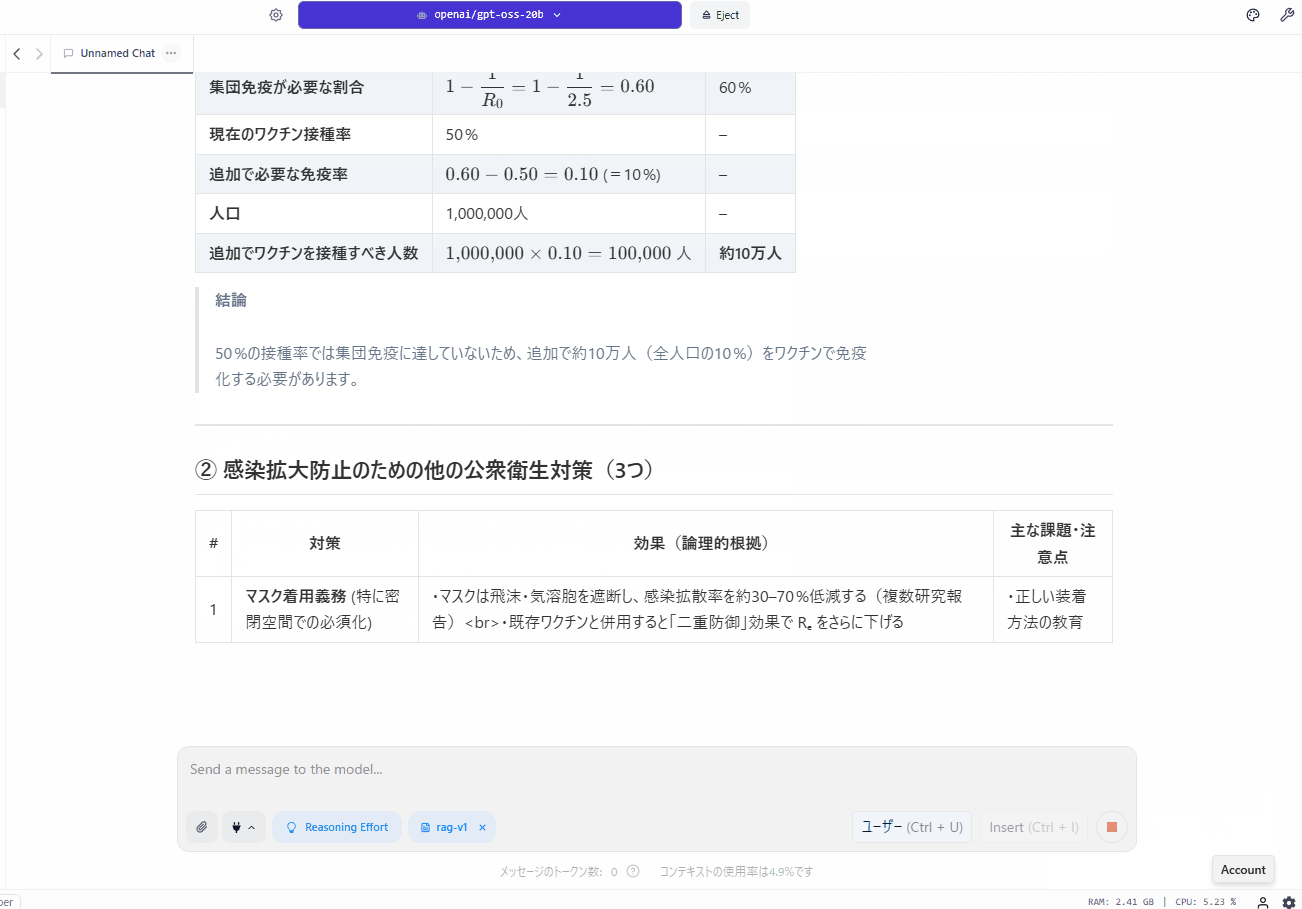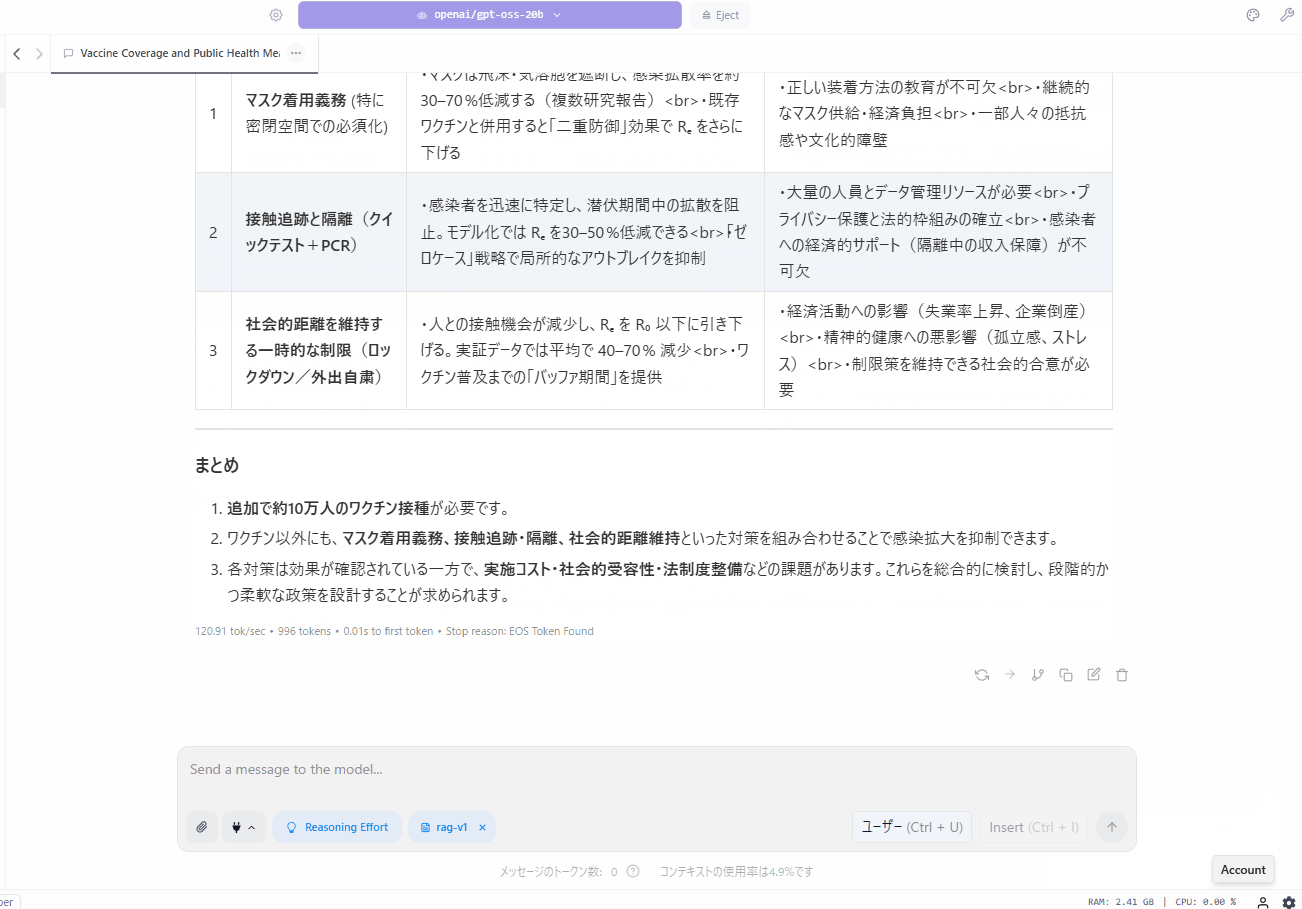
メインマシンの環境であればGPUオフロードを最大値にしても、VSCodeの利用であったりGoogle Chromeで複数タブ開いて操作していても、何ら問題なく動作してくれます。
GPUオフロード値がデフォルトの23で実行した場合、1秒あたりに出力できるトークン数が約1/3になるので特に大きな理由も無い限りはGPUオフロードの値は最大値の24で良さそう。
M4 mac miniはそこまで奮わず
M4 mac miniは搭載しているユニファイドメモリのサイズが小さいこともあって、パフォーマンスガードレールを設定していると、モデルの読み込みに失敗します。
パフォーマンスガードレールをなしにすれば、ブラウザでChatGPTを利用したときより少し遅い物の、十分実用的な速度で出力してくれます。
ただし、メモリの使用量がほぼ限界値に張り付くので、モデルをロードした状態で他作業を実施するには少し厳しそう。
僕自身M4 mac miniはLLMをぶん回すためだけのデバイスとして購入しているので、今現状の1台構成でもLMStudioをリモートから叩けりゃ良いので、特に問題は無いかなと。
しかし、他のアプリケーションも併せて利用するのであれば、かなり厳しい結果に。
まだexoクラスタ組めていないのでなんともですが、2台構成でどれくらいのスピードになるかちょい楽しみ。
gpt-oss-120bをメインマシンで動かしてみた
さて、僕のメインマシンですが搭載しているメモリが128GBということもあって、gpt-oss-120bも読み込みはできるので、試しに実行してました。
gpt-oss-120bを動かす際も、GPUオフロード値をデフォルト値と最大値それぞれに設定し、gpt-oss-20bで利用したテストプロンプトを試しに流してみました。
gpt-oss-120b テストパターン
テストパターンは以下の通りです。
- パターンA:コンテキスト長:4096、GPUオフロード:36
- パターンB:コンテキスト長:4096、GPUオフロード:6 ※デフォルト値
結果
それぞれのパターンでテストプロンプトを実行した結果は以下の通りです。
| パターン | 1秒あたりに出力できるトークン数(tok/sec) |
| パターンA | 8.23 tok/sec |
| パターンB | 9.67 tok/sec |
gpt-oss-20bと比べると雲泥の差ではある物の、ギリギリ使えないこともないスピードで出力できました。
モデルサイズが大きくなって、GPUのVRAM上に展開しきれなくなると、RAM上に展開し始めるのですがそうなると比べものにならないほど遅くなることは想定していたのですが、結果としては思いのほか良好でした。
個人的な利用でgpt-oss-20bでは充足できない要件は基本的にないはずですが、より深い推論が必要になった場合はメインマシンのスペックであれば、一応動かせんこともない感じです。
こぼれ話:Amazon Bedrockでもオレゴン(us-west-2)リージョンならリクエスト可能
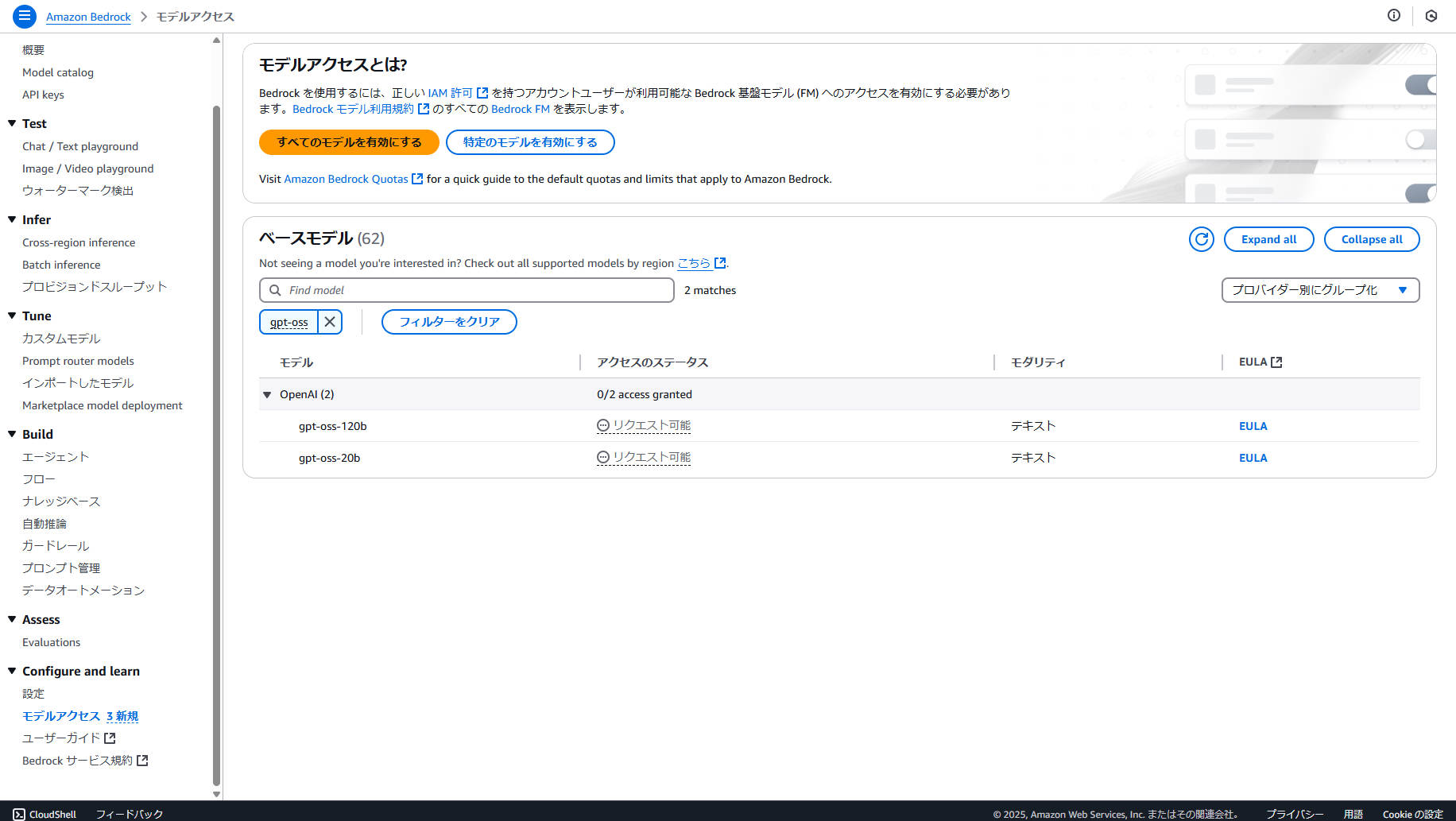
Amazon Bedrockでもオレゴン(us-west-2)リージョンならリクエスト可能になっていたので、業務利用においても結構効いてきそうです。
残念ながら東京(ap-northeast-1)は記事執筆時点の2025年8月7日 2:00時点では選択できなかったので、東京リージョンで利用したい場合は、もう少し待たないとですね。
エッジ利用ではgpt-oss-20bで十分かも
gpt-oss-20bもOpenAI o3‑miniと同等の性能を発揮するので、エッジ利用であればgpt-oss-20bで良さそうなぁと。
今までは使うモデルをいろいろ取っ替え引っ替えして試していたのですが、しばらくはgpt-oss-20bをぶん回してみようと思います。
